表、索引
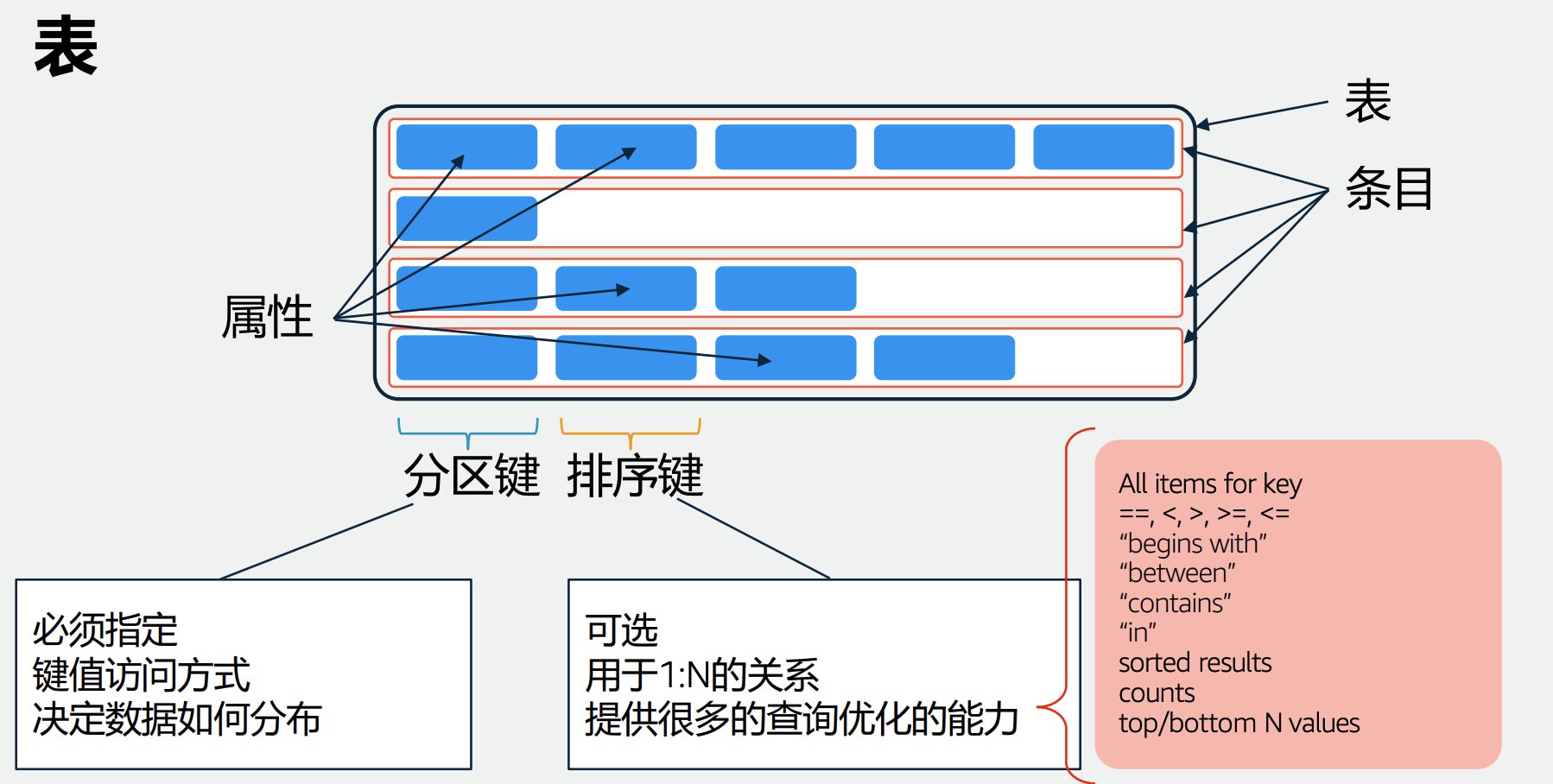
分区键和排序键共同唯一的标识一条记录
本地二级索引 Local Secondary Index (LSI) 单表上的。可以选择与表不同的排序键。同一个分区键。强一致性更新。
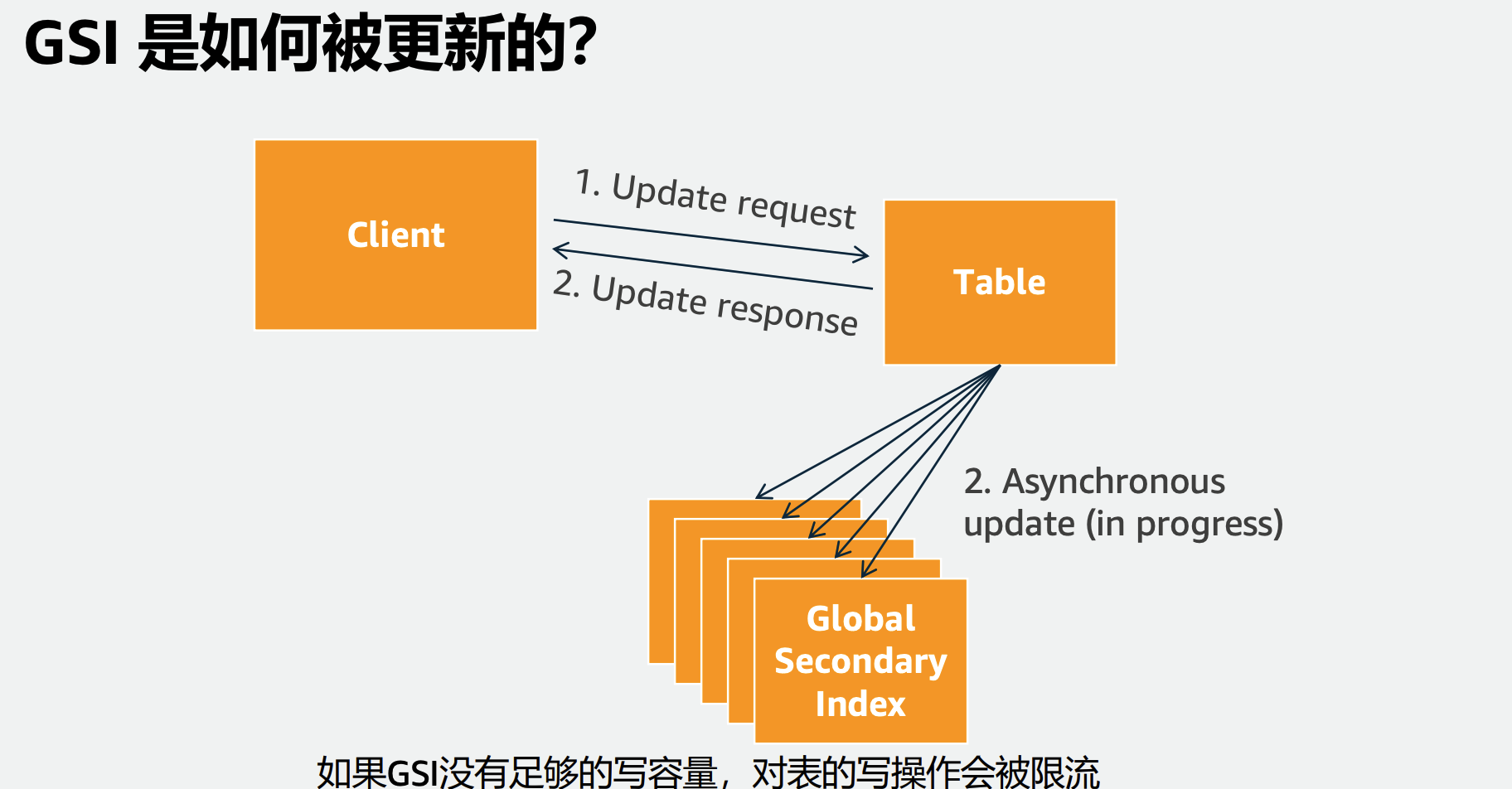
全局二级索引 - Global Secondary Index (GSI) 可以选择与表不同的分区键以及排序键 每个索引分区会对应所有的表分区
对比
- Global Secondary
- 索引的尺寸没有上限
- 读写容量和表是独立的
- 只支持最终一致性
- Index Local Secondary Index
- 索引保存在表的分区中,因此一个表 分区的尺寸的上限是10GB
- 使用的是表上定义的RCU和WCU
- 强一致性
索引指向的是实际存储,可以理解为空间指针。并不是数据的拷贝。像mysql B树指向主键一样。
实现
Dynamo在某些故障的场景中将牺牲一致性。
Dynamo的系统假设和要求: 1)query model:对数据项简单的读,写是通过一个主键唯一性标识。状态存储为一个由唯一性键确定二进制对象。没有横跨多个数据项的操作,也不需要关系方案(relational schema)。这项规定是基于观察相当一部分Amazon的服务可以使用这个简单的查询模型,并不需要任何关系模式。Dynamo的目标应用程序需要存储的对象都比较小(通常小于1MB)。
2)ACID属性:ACID是一种保证数据库事务可靠地处理的属性。在数据库方面的,对数据的单一的逻辑操作被称作所谓的交易。Amazon的经验表明,在保证ACID的数据存储提往往有很差的可用性。Dynamo的目标应用程序是高可用性,弱一致性(ACID“中的C”)。Dynamo不提供任何数据隔离(Isolation)保证,只允许单一的关键更新。
3)efficiency:系统需运作在一般的commodity hardware上。Amazon平台的服务都有着严格的延时要求, 鉴于对状态的访问在服务操作中起着至关重要的作用,存储系统必须能够满足那些严格的SLA,服务必须能够通过配置Dynamo,使他们不断达到延时和吞吐量的要求。因此,必须在成本效率,可用性和耐用性保证之间做权衡。
提供get, put操作。
最终一致性。
Partition
按key做partition, 一致性Hash。
Replication
replica, 复制,用了NWR,让用户做一致性的选择。读数据时如果有不同版本,会所有版本数据都返回回去。
Data Versioning
多版本。Vector Clock 一个Vector Clock可以理解为一个<节点编号,计数器>对的列表。每一个版本的数据都会带上一个Vector Clock。Dynamo中,最重要的是要保证写操作的高可用性,即“Always Writeable”,这样就不可避免的牺牲掉数据的一致性。如上所述,Dynamo中并没有对数据做强一致性要求,而是采用的最终一致性(eventual consistency)。若不保证各个副本的强一致性,则用户在读取数据的时候很可能读到的不是最新的数据。Dynamo中将数据的增加或删除这种操作都视为一种增加操作,即每一次操作的结果都作为一份全新的数据保存,这样也就造成了一份数据会存在多个版本,分布在不同的节点上。这种情况类似于版本管理中的多份副本同时有多人在修改。多数情况下,系统会自动合并这些版本,一旦合并尝试失败,那么冲突的解决就交给应用层来解决。这时系统表现出来的现象就是,一个GET(KEY)操作,返回的不是单一的数据,而是一个多版本的数据列表,由用户决定如何合并。这其中的关键技术就是Vector Clock。
其实就是读修复。
Failure Detection
临时性故障,采用Hinted Handoff提示移交机制
为防止要写入节点宕机导致操作失败,采用提示移交机制将操作相关数据写入到随机节点,宕机节点恢复后可根据这些数据进行重放,最终获得数据一致性。
以N=3为例,如果在一次写操作时发现节点A挂了,那么本应该存在A上的副本就会发送到D上,同时在D中会记录这个副本的元信息(MetaData)。其中有个标示,表明这份数据是本应该存在A上的,一旦节点D之后检测到A从故障中恢复了,D就会将这个本属于A的副本回传给A,之后删除这份数据。Dynamo中称这种技术为“Hinted Handoff”。
另外为了应对整个机房掉线的故障,Dynamo中应用了一个很巧妙的方案。每次读写都会从”Preference List”列表中取出R或W个节点。那么只要在这个列表生成的时候,让其中的节点是分布于不同机房的,自然数据就写到了不同机房的节点上。
对于某节点非临时性故障,利用反熵得到丢失数据进行恢复。一些数据存储有后台进程,不断查找副本之间的数据差异,将任何缺少的数据从一个副本复制到另一个副本。和基于主节点复制的复制日志不同,此反熵过程不保证任何特定的顺序复制写入,并且会引入明显的同步滞后
事务
支持事务,所有操作必须成功完成,否则不会进行任何更改。
隔离级别:
- 可序列化
- 读已提交
通过乐观锁和版本实现的事务,事务只能读已提交,提交时判断条件不符合,以及版本不对,就回滚。
其他
begin_with这个操作要记得。其他后面看。begin_with是字符串前缀匹配,应该用了字典树等加速。
没啥子东西,数据操作优先同区域内,主要靠复制。
没啥东西
getItem、query和scan
这三个操作都是查询操作,效率分别是:getItem > query > scan
getItem是根据primary key进行查询,可以理解为通过primary key在hashMap上查询,速度是最快的,缺点是必须知道primary key且只能查询单个,使用情况相对较少。
scan是全表扫描,是最慢的一个,理论上能不用就不用,只有实在走投无路才考虑全表扫描。
query是最常见的方式,在dynamoDB的使用中,我们唯一的目的就是写出高效的查询query。