算法 = 思路 + 实现
思考原则
- 朴素方法,从前往后看有没有可优化的。
- dp方法,就是深入到局部。
- 从后往前,比如对结果的二分等。
局部原则
局部原则,从一个点,从一个索引位置去考虑。
根据时间复杂度找思路
根据时间复杂度做题的具体流程:
- 根据数据范围选择时间复杂度
- 根据时间复杂度选择对应的常见算法集合
- 思考题目特征,从集合中选出合适的算法
- 根据选出的算法求解题目
根据数据范围找时间复杂度
通常来说,在力扣上,Python 可以支持到 10^7 的时间复杂度;C++ 会稍微多一点,大概 10^7 - 10^8 之间。因此我们可以得到如下表所示的,数据范围与算法大致时间复杂度的对应表。

根据时间复杂度找算法
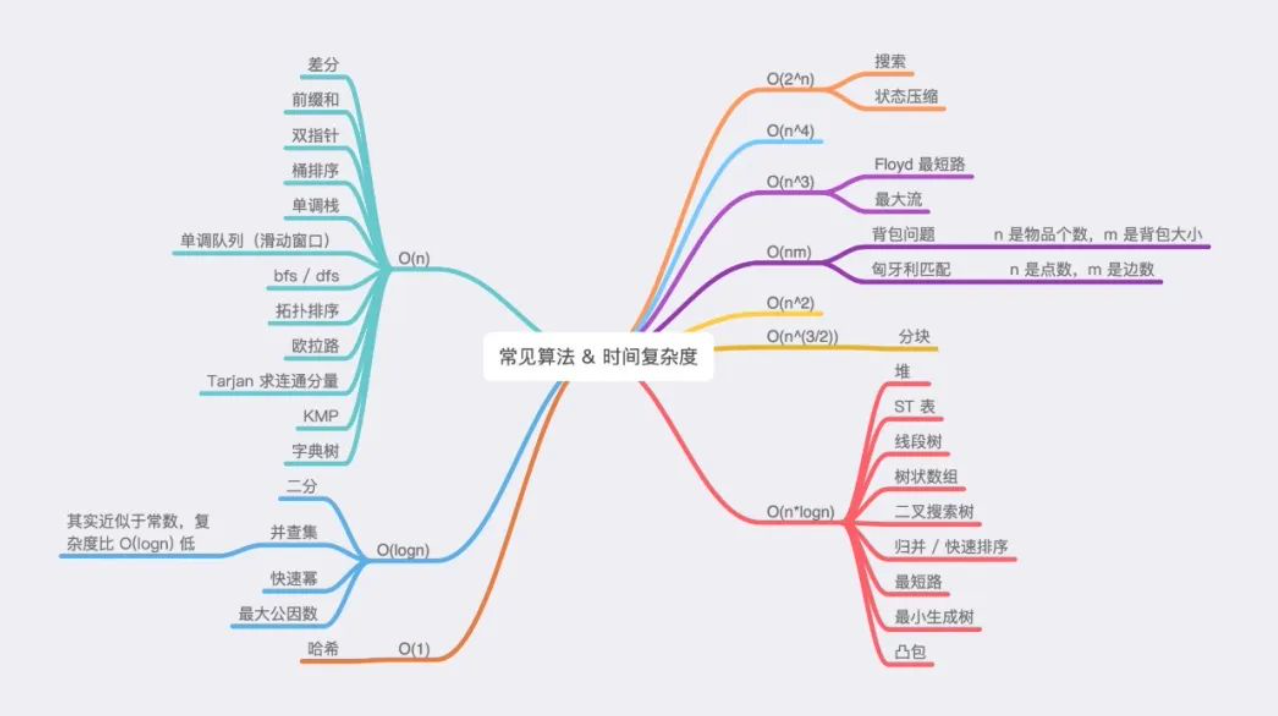
n<=6,基本是回溯法,阶乘。
n≤30, 指数级别, dfs+剪枝,状态压缩dp
n≤100=> O(n3),floyd,dp,高斯消元
n≤1000 => O(n2),O(n2logn),dp,二分,朴素版Dijkstra、朴素版Prim、Bellman-Ford
n≤10000 => O(n∗n‾√)O(n∗n),块状链表、分块、莫队
n≤100000 => O(nlogn)=> 各种sort,线段树、树状数组、set/map、heap、拓扑排序、dijkstra+heap、
prim+heap、spfa、求凸包、求半平面交、二分、CDQ分治、整体二分
n≤1000000 => O(n)O(n), 以及常数较小的 O(nlogn)O(nlogn) 算法 => 单调队列、 hash、双指针扫描、并查集,kmp、AC自动机,常数比较小的 O(nlogn)O(nlogn) 的做法:sort、树状数组、heap、dijkstra、spfa
n≤10000000 => O(n)O(n),双指针扫描、kmp、AC自动机、线性筛素数
n≤109 => O(n‾√)O(n),判断质数
n≤1018 => O(logn)O(logn),最大公约数,快速幂
n≤101000 => O((logn)2)O((logn)2),高精度加减乘除
n≤10100000 => O(logk×loglogk),k表示位数O(logk×loglogk),k表示位数,高精度加减、FFT/NTT
根据题目特征找思路
求符合要求的全部结果
- 求全部全排列
- 回溯法 o(n!)
- 求全部子序列
- 回溯法 o(2^n)
- 子集生成法 2^20以内,也就是n<=20
- 求全部子数组
- 双指针
求方法数
求最优目标值
最优目标值: max, min, equal等
- 求某个子序列的最优目标值
- 回溯法 o(2^n)
- 子集生成法 2^20以内,也就是n<=20
- 动态规划
- 单调栈、单调队列
- 求某个子数组的最优目标值
- 前缀和,比如带负数的数组求是否有子数组=S。 后缀和
- 动态规划
- 滑动窗口
- 求全部最优目标值
- 维持maxnum,minnum
BST
- 可以多多考虑下upper bound 和lower bound的思想。
- 比如题目 前序遍历构造二叉搜索树
- 山脉数组好像也是,待定
找第k小
- 堆
- 二分,结果符合单调性。
图
建反向边 bfs
求多源距离点A的最短路径,转化位点A到多源最短路径.
参考题目:
为什么图最短路径不能树形dp求?因为树形dp要求两个节点之间至多只有一条路径。
DAG求最长路径

dp. 参考
找升序数组两个数字交换后的两个位置
public int[] findTwoSwapped(List<Integer> nums) {
int n = nums.size();
int x = -1, y = -1;
for (int i = 0; i < n - 1; ++i) {
if (nums.get(i + 1) < nums.get(i)) {
y = nums.get(i + 1);
if (x == -1) {
x = nums.get(i);
} else {
break;
}
}
}
return new int[]{x, y};
}
计算小于等于这个中间值的任意两个数的差的绝对值有几个
# 双指针
def count_not_greater(diff):
i = ans = 0
for j in range(1, len(A)):
while A[j] - A[i] > diff:
i += 1
ans += j - i
return ans
求nums符合条件的(i,j)的数量
可以动态维护一个数组d, 然后遍历nums,从d里查找计数,然后再插入到d里,统计数量也没有多统计。
前缀和
前缀和里一定要有0.
nums = [12,3,4]
pre = [0 for _ in range(len(nums))]
for i,v in enumerate(nums):
pre[i+1] = pre[i]+v
前缀和+hash表
可方便计算利用前缀和的第一次出现位置,就是hash存的第一次位置,用于求最长区间。,1371. 每个元音包含偶数次的最长子字符串
也可以方便计算前缀和出现了多少次,用于计算多少个子数组和为k.
逆向思考
https://leetcode-cn.com/problems/bricks-falling-when-hit/solution/803-da-zhuan-kuai-by-leetcode-r5kf/
逆向去考虑一个问题的思路其实在「力扣」上并不少见,感兴趣的朋友可以复习一下我们在打卡题中曾经做过的:174. 地下城游戏 和 312. 戳气球。
各种算法特征
枚举
枚举的思想是不断地猜测,从可能的集合中一一尝试,然后再判断题目的条件是否成立。
注意枚举空间、枚举顺序。
模拟
模拟就是用计算机来模拟题目中要求的操作。
模拟题目通常具有码量大、操作多、思路繁复的特点。由于它码量大,经常会出现难以查错的情况,如果在考试中写错是相当浪费时间的。
递归、分治
明白一个函数的作用并相信它能完成这个任务,千万不要跳进这个函数里面企图探究更多细节
贪心
贪心算法(英语:greedy algorithm),是用计算机来模拟一个“贪心”的人做出决策的过程。这个人十分贪婪,每一步行动总是按某种指标选取最优的操作。而且他目光短浅,总是只看眼前,并不考虑以后可能造成的影响。
贪心算法在有最优子结构的问题中尤为有效。最优子结构的意思是问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解。1
证明方法
贪心算法有两种证明方法:反证法和归纳法。一般情况下,一道题只会用到其中的一种方法来证明。
- 反证法:如果交换方案中任意两个元素/相邻的两个元素后,答案不会变得更好,那么可以推定目前的解已经是最优解了。
- 归纳法:先算得出边界情况(例如 )的最优解 ,然后再证明:对于每个n , Fn+1都可以由Fn推导出结果。
常见题型
在提高组难度以下的题目中,最常见的贪心有两种。
- 「我们将 XXX 按照某某顺序排序,然后按某种顺序(例如从小到大)选择。」。
- 「我们每次都取 XXX 中最大/小的东西,并更新 XXX。」(有时「XXX 中最大/小的东西」可以优化,比如用优先队列维护)
二者的区别在于一种是离线的,先处理后选择;一种是在线的,边处理边选择。
排序解法
用排序法常见的情况是输入一个包含几个(一般一到两个)权值的数组,通过排序然后遍历模拟计算的方法求出最优值。
后悔解法
思路是无论当前的选项是否最优都接受,然后进行比较,如果选择之后不是最优了,则反悔,舍弃掉这个选项;否则,正式接受。如此往复。
前缀和 & 差分
前缀和是一种重要的预处理,能大大降低查询的时间复杂度。可以简单理解为“数列的前 项的和”。
差分是前缀和逆运算
知识点:
- 二维前缀和,可用于01矩阵里求最大正方形计算。
m,n = len(matrix), len(matrix[0])
# 建立
pre = [[0 for _ in range(n + 1)] for _ in range(m + 1)]
for i in range(1, m+1):
for j in range(1, n +1):
pre[i][j] = pre[i-1][j]+ pre[i][j-1] - pre[i-1][j-1] + matrix[i-1][j-1]
# 使用,等价于以(x1,y1)为矩阵左上角以(x2,y2)为矩阵右下角的所有格子的和
pre[x2+1][y2+1] + pre[x1][y1] - pre[x1][y2+1] - pre[x2+1][y1]
二叉树
双递归,就是递归调用自己同时触发另一个函数递归,比如树上找一条路径和为k.
全局记录最大值,把递归变成可复用的,中间更新最大值。比如树上找最大路径,return一条边最大的。
二分
最大值最小化
要求满足某种条件的最大值的最小可能情况(最大值最小化),首先的想法是从小到大枚举这个作为答案的「最大值」,然后去判断是否合法。若答案单调,就可以使用二分搜索法来更快地找到答案。因此,要想使用二分搜索法来解这种「最大值最小化」的题目,需要满足以下三个条件:
- 答案在一个固定区间内;
- 可能查找一个符合条件的值不是很容易,但是要求能比较容易地判断某个值是否是符合条件的;
- 可行解对于区间满足一定的单调性。换言之,如果 是符合条件的,那么有 或者 也符合条件。(这样下来就满足了上面提到的单调性)
当然,最小值最大化是同理的。
相关题目:
如果已知结果范围,也可以根据对结果范围进行递归。其实就是上面这种,比如
倍增法
倍增法(英语:binary lifting),顾名思义就是翻倍。它能够使线性的处理转化为对数级的处理,大大地优化时间复杂度。
这个方法在很多算法中均有应用,其中最常用的是 RMQ 问题和求 LCA(最近公共祖先) 。
ST(Sparse Table)表,中文名稀疏表,是一种数据结构。
ST表常用于解决可重复贡献问题。
什么是可重复贡献问题?
举例来说:要你求10个数中的最大数,你完全可以先求前6个数的 ,再求后7个数的
,然后再对所求的两个最大数求
。虽然中间有几个数被重复计算了,但并不影响最后的答案。
常见的可重复贡献问题有:区间最值、区间按位和、区间按位或、区间GCD等。而像区间和这样的问题就不是可重复贡献问题。
f[i][j] = max(f[i][j - 1], f[i + (1 << (j - 1))][j - 1])
博弈论
双指针
搜索
dfs, 注意dfs可以使用color[u]的
图的bfs需要入队前标志visit, 而树或者最短路径dijstra需要出队标志visit.
注意复杂度太高的话,可以拆分成两半后在合到一起
bfs分两种,一种是单源的,一种是多源(多目的地反过来)的,多源一般要反向边来搞,比如题目。
动态规划
动态规划(Dynamic programming,简称 DP)是一种在数学、管理科学、计算机科学、经济学和生物信息学中使用的,通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。
动态规划常常适用于有重叠子问题和最优子结构性质的问题,动态规划方法所耗时间往往远少于朴素解法。
背包问题
小优化: 根据贪心原理,当费用相同时,只需保留价值最高的;当价值一定时,只需保留费用最低的;
变种:
- 求输出方案, g(i,u)表示第i件物品占用空间为u 的时候是否选择了此物品
- 求方案数
- 求最优方案总数
区间DP
合并:即将两个或多个部分进行整合,当然也可以反过来;
特征:能将问题分解为能两两合并的形式;
求解:对整个问题设最优值,枚举合并点,将问题分解为左右两个部分,最后合并两个部分的最优值得到原问题的最优值。
怎样处理环?

树形dp
拓扑排序
单调队列
字符串
位运算
栈
栈常见的应用有进制转换,括号匹配,栈混洗,中缀表达式(用的很少),后缀表达式(逆波兰表达式)等。